如何实现新引擎
1. Linkis新引擎功能代码实现
实现一个新的引擎其实就是实现一个新的EngineConnPlugin(ECP)引擎插件。具体步骤如下:
1.1 新建一个maven模块,并引入ECP的maven依赖
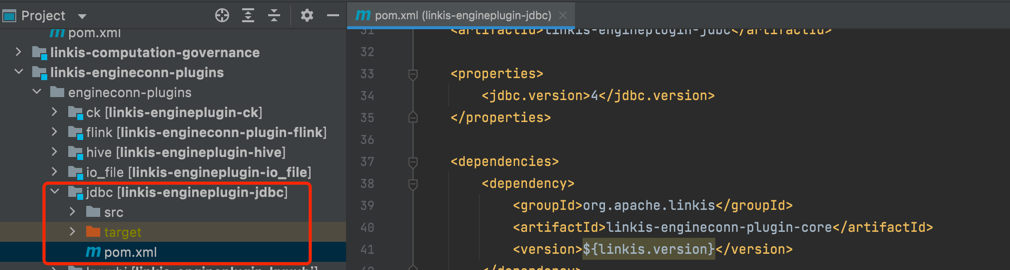
<dependency>
<groupId>org.apache.linkis</groupId>
<artifactId>linkis-engineconn-plugin-core</artifactId>
<version>${linkis.version}</version>
</dependency>
<!-- 以及一些其他所需依赖的maven配置 -->
1.2 实现ECP的主要接口
EngineConnPlugin: 启动EngineConn时,先找到对应的EngineConnPlugin类,以此为入口,获取其它核心接口的实现,是必须实现的主要接口。
EngineConnFactory: 实现如何启动一个引擎连接器,和如何启动一个引擎执行器的逻辑,是必须实现的接口。
- 实现createEngineConn方法:返回一个EngineConn对象,其中,getEngine返回一个封装了与底层引擎连接信息的对象,同时包含Engine类型信息。
- 对于只支持单一计算场景的引擎,继承SingleExecutorEngineConnFactory,实现createExecutor,返回对应的Executor。
- 对于支持多计算场景的引擎,需要继承MultiExecutorEngineConnFactory,并为每种计算类型实现一个ExecutorFactory。EngineConnPlugin会通过反射获取所有的ExecutorFactory,根据实际情况返回对应的Executor。
EngineConnResourceFactory: 用于限定启动一个引擎所需要的资源,引擎启动前,将以此为依 据 向 Linkis Manager 申 请 资 源。非必须,默认可以使用GenericEngineResourceFactory。
EngineLaunchBuilder: 用于封装EngineConnManager可以解析成启动命令的必要信息。非必须,可以直接继承JavaProcessEngineConnLaunchBuilder。
1.3 实现引擎Executor执行器逻辑
Executor为执行器,作为真正的计算场景执行器,是实际的计算逻辑执行单元,也是对引擎各种具体能力的抽象,提供加锁、访问状态、获取日志等多种不同的服务。并根据实际的使用需要,Linkis默认提供以下的派生Executor基类,其类名和主要作用如下:
- SensibleExecutor:
- Executor存在多种状态,允许Executor切换状态
- Executor切换状态后,允许做通知等操作
- YarnExecutor: 指Yarn类型的引擎,能够获取得到applicationId和applicationURL和队列。
- ResourceExecutor: 指引擎具备资源动态变化的能力,配合提供requestExpectedResource方法,用于每次希望更改资源时,先向RM申请新的资源;而resourceUpdate方法,用于每次引擎实际使用资源发生变化时,向RM汇报资源情况。
- AccessibleExecutor: 是一个非常重要的Executor基类。如果用户的Executor继承了该基类,则表示该Engine是可以被访问的。这里需区分SensibleExecutor的state()和 AccessibleExecutor 的 getEngineStatus()方法:state()用于获取引擎状态,getEngineStatus()会获取引擎的状态、负载、并发等基础指标Metric数据。
- 同时,如果继承了 AccessibleExecutor,会触发Engine 进程实例化多个EngineReceiver方法。EngineReceiver用于处理Entrance、EM和LinkisMaster的RPC请求,使得该引擎变成了一个可被访问的引擎,用户如果有特殊的RPC需求,可以通过实现RPCService接口,进而实现与AccessibleExecutor通信。
- ExecutableExecutor: 是一个常驻型的Executor基类,常驻型的Executor包含:生产中心的Streaming应用、提交给Schedulis后指定要以独立模式运行的脚步、业务用户的业务应用等。
- StreamingExecutor: Streaming为流式应用,继承自ExecutableExecutor,需具备诊断、do checkpoint、采集作业信息、监控告警的能力。
- ComputationExecutor: 是常用的交互式引擎Executor,处理交互式执行任务,并且具备状态查询、任务kill等交互式能力。
- ConcurrentComputationExecutor: 用户并发引擎Executor,常用于JDBC类型引擎,执行脚本时,由管理员账户拉起引擎实例,所有用户共享引擎实例。
2. 以JDBC引擎为例详解新引擎的实现步骤
本章节以JDBC引擎举例,详解新引擎的实现过程,包括引擎代码的编译、安装、数据库配置,管理台引擎标签适配,以及Scripts中新引擎脚本类型扩展和工作流新引擎的任务节点扩展等。
2.1 并发引擎设置默认启动用户
JDBC引擎中的核心类JDBCEngineConnExecutor继承的抽象类是ConcurrentComputationExecutor,计算类引擎中的核心类XXXEngineConnExecutor继承的抽象类是ComputationExecutor。这导致两者最大的一个区别是:JDBC引擎实例由管理员用户启动,被所有用户共享,以提高机器资源利用率;而计算引擎类型的脚本在提交时,每个用户下会启动一个引擎实例,用户间引擎实例互相隔离。这个在此处暂不细说,因为无论是并发引擎还是计算引擎,下文提到的额外修改流程应是一致的。
相应的,如果你新增的引擎是并发引擎,那么你需要关注下这个类:AMConfiguration.scala,如果你新增的引擎是计算类引擎,则可忽略。
object AMConfiguration {
// 如果你的引擎是多用户并发引擎,那么这个配置项需要关注下
val MULTI_USER_ENGINE_TYPES = CommonVars("wds.linkis.multi.user.engine.types", "jdbc,ck,es,io_file,appconn")
private def getDefaultMultiEngineUser(): String = {
// 此处应该是为了设置并发引擎拉起时的启动用户,默认jvmUser即是引擎服务Java进程的启动用户
val jvmUser = Utils.getJvmUser
s"""{jdbc:"$jvmUser", presto: "$jvmUser" es: "$jvmUser", ck:"$jvmUser", appconn:"$jvmUser", io_file:"root"}"""
}
}
2.2 新引擎类型扩展
实现ComputationSingleExecutorEngineConnFactory接口的类JDBCEngineConnFactory中,下面两个方法需要实现:
override protected def getEngineConnType: EngineType = EngineType.JDBC
override protected def getRunType: RunType = RunType.JDBC
因此需要在EngineType和RunType中增加JDBC对应的变量。
// EngineType.scala中类似已存在引擎的变量定义,增加JDBC相关变量或代码
object EngineType extends Enumeration with Logging {
val JDBC = Value("jdbc")
}
def mapStringToEngineType(str: String): EngineType = str match {
case _ if JDBC.toString.equalsIgnoreCase(str) => JDBC
}
// RunType.scla中
object RunType extends Enumeration {
val JDBC = Value("jdbc")
}
2.3 JDBC引擎标签中的版本号设置
// 在LabelCommonConfig中增加JDBC的version配置
public class LabelCommonConfig {
public final static CommonVars<String> JDBC_ENGINE_VERSION = CommonVars.apply("wds.linkis.jdbc.engine.version", "4");
}
// 在EngineTypeLabelCreator的init方法中补充jdbc的匹配逻辑
// 如果这一步不做,代码提交到引擎上时,引擎标签信息中会缺少版本号
public class EngineTypeLabelCreator {
private static void init() {
defaultVersion.put(EngineType.JDBC().toString(), LabelCommonConfig.JDBC_ENGINE_VERSION.getValue());
}
}
2.4 允许脚本编辑器打开的脚本文件类型
关注配置项:wds.linkis.storage.file.type
object LinkisStorageConf{
val FILE_TYPE = CommonVars("wds.linkis.storage.file.type", "dolphin,sql,scala,py,hql,python,out,log,text,sh,jdbc,ngql,psql,fql").getValue
}
2.5 配置JDBC脚本变量存储和解析
如果这个操作不做,JDBC的脚本中变量不能被正常存储和解析,脚本中直接使用${变量}时代码会执行失败!
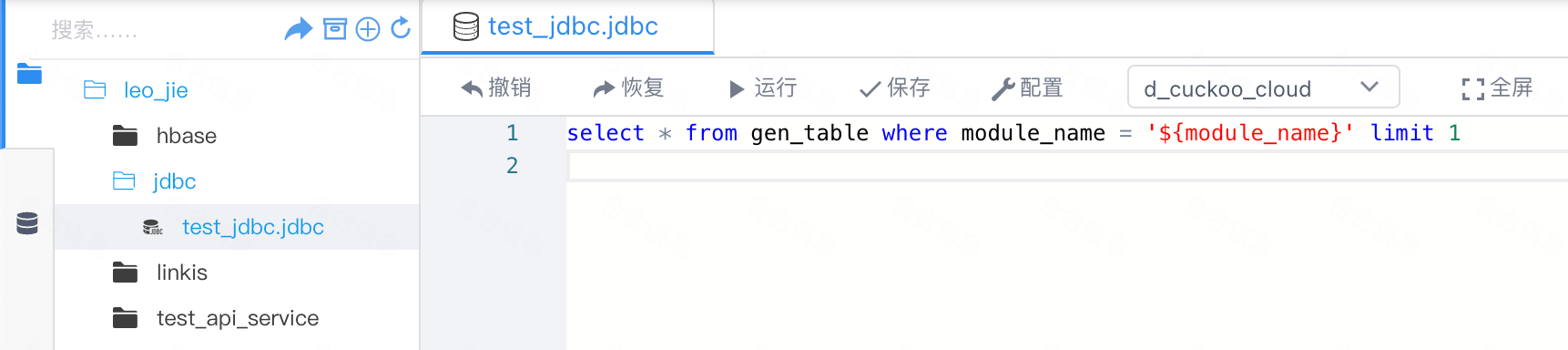
// 通过CodeAndRunTypeUtils工具类中的CODE_TYPE_AND_RUN_TYPE_RELATION变量来维护codeType和runType间的对应关系
val CODE_TYPE_AND_RUN_TYPE_RELATION = CommonVars("wds.linkis.codeType.runType.relation", "sql=>sql|hql|jdbc|hive|psql|fql,python=>python|py|pyspark,java=>java,scala=>scala,shell=>sh|shell")
参考PR:https://github.com/apache/linkis/pull/2047
2.6 Linkis管理员台界面引擎管理器中加入JDBC引擎文字提示或图标
linkis-web/src/dss/module/resourceSimple/engine.vue
methods: {
calssifyName(params) {
switch (params) {
case 'jdbc':
return 'JDBC';
......
}
}
// 图标过滤
supportIcon(item) {
const supportTypes = [
......
{ rule: 'jdbc', logo: 'fi-jdbc' },
];
}
}
最终呈现给用户的效果:
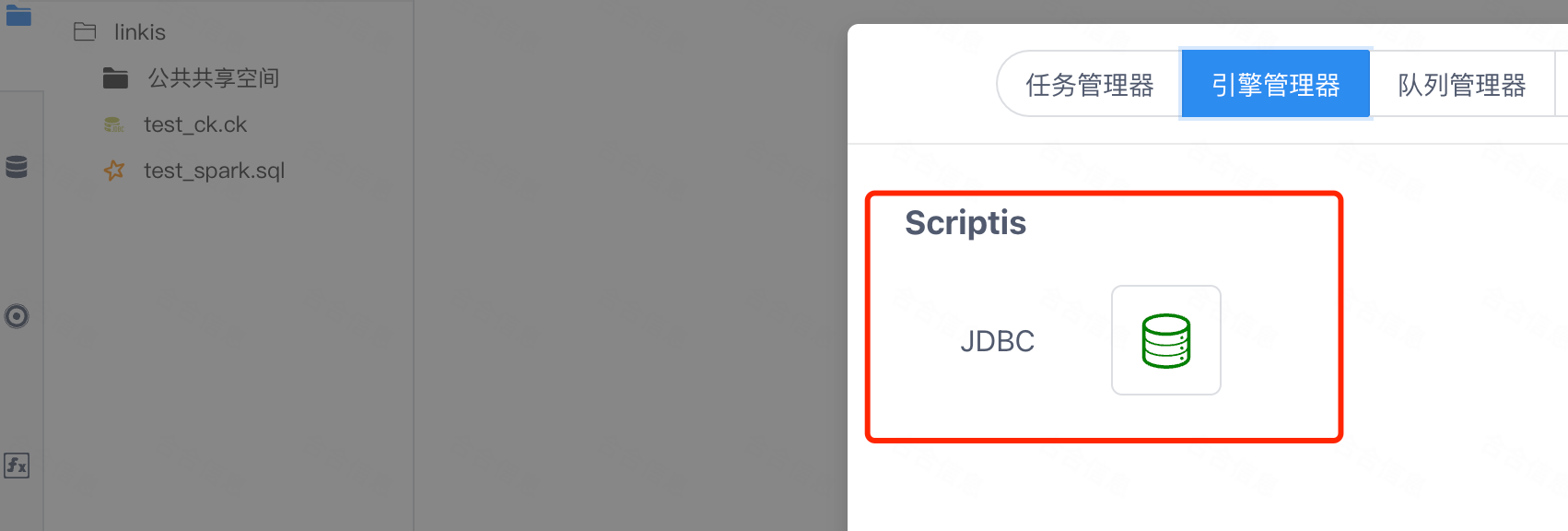
2.7 JDBC引擎的编译打包和安装部署
JDBC引擎模块编译的示例命令如下:
cd /linkis-project/linkis-engineconn-pluginsengineconn-plugins/jdbc
mvn clean install -DskipTests
编译完整项目时,新增引擎默认不会加到最终的tar.gz压缩包中,如果需要,请修改如下文件:
linkis-dist/src/main/assembly/distribution.xml
<!--jdbc-->
<fileSets>
......
<fileSet>
<directory>
../linkis-engineconn-plugins/jdbc/target/out/
</directory>
<outputDirectory>linkis-package/lib/linkis-engineconn-plugins/</outputDirectory>
<includes>
<include>**/*</include>
</includes>
</fileSet>
</fileSets>
然后对在项目根目录运行编译命令:
mvn clean install -DskipTests
编译成功后在linkis-dist/target/apache-linkis-1.x.x-bin.tar.gz和linkis-engineconn-plugins/jdbc/target/目录下找到out.zip。
上传out.zip文件到Linkis的部署节点,解压缩到Linkis安装目录/lib/linkis-engineconn-plugins/下面:
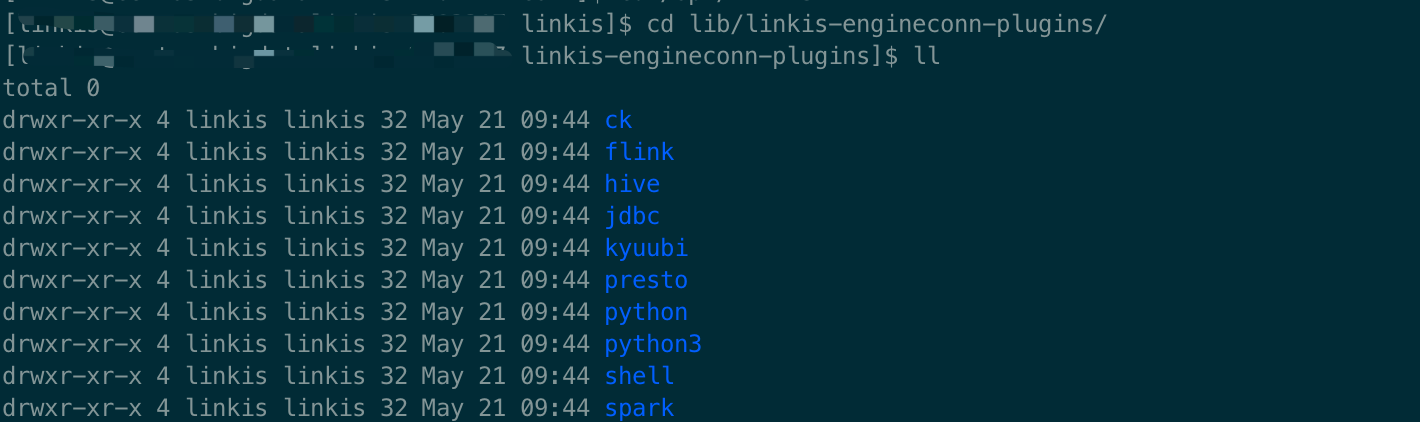
解压后别忘记删除out.zip,至此引擎编译和安装完成。
2.8 JDBC引擎数据库配置
在管理台选择添加引擎
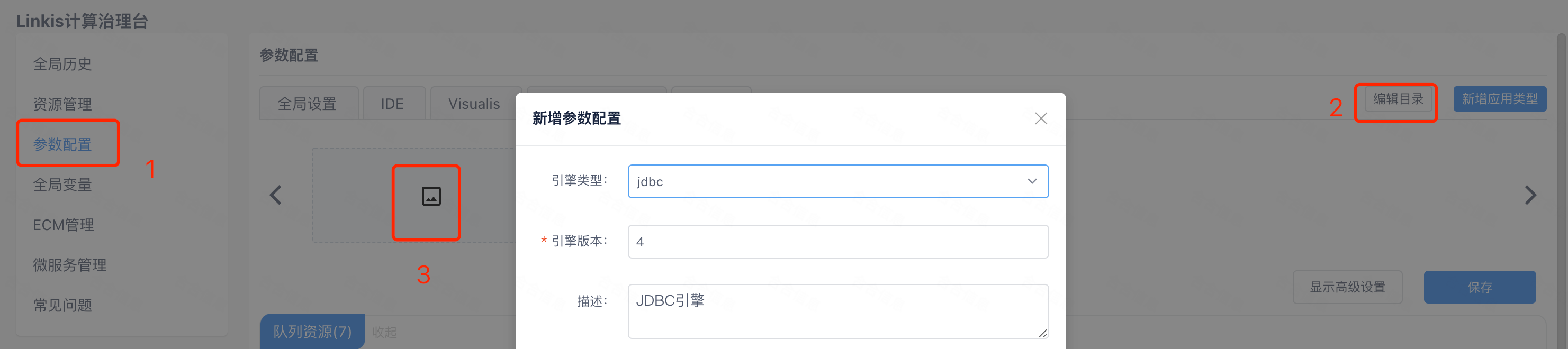
如果您希望在管理台支持引擎参数配置,可以按照JDBC引擎SQL示例修改数据库。
此处以JDBC引擎为例,引擎安装完之后,要想运行新的引擎代码,还需对引擎进行数据库配置,以JDBC引擎为例,按照你自己实现的新引擎的情况,请按需修改。
SQL参考如下:
SET @JDBC_LABEL="jdbc-4";
SET @JDBC_ALL=CONCAT('*-*,',@JDBC_LABEL);
SET @JDBC_IDE=CONCAT('*-IDE,',@JDBC_LABEL);
SET @JDBC_NODE=CONCAT('*-nodeexecution,',@JDBC_LABEL);
-- JDBC
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.rm.instance', '范围:1-20,单位:个', 'jdbc引擎最大并发数', '2', 'NumInterval', '[1,20]', '0', '0', '1', '队列资源', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.driver', '取值范围:对应JDBC驱动名称', 'jdbc驱动名称','', 'None', '', '0', '0', '1', '数据源配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.connect.url', '例如:jdbc:hive2://127.0.0.1:10000', 'jdbc连接地址', 'jdbc:hive2://127.0.0.1:10000', 'None', '', '0', '0', '1', '数据源配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.version', '取值范围:jdbc3,jdbc4', 'jdbc版本','jdbc4', 'OFT', '[\"jdbc3\",\"jdbc4\"]', '0', '0', '1', '数据源配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.connect.max', '范围:1-20,单位:个', 'jdbc引擎最大连接数', '10', 'NumInterval', '[1,20]', '0', '0', '1', '数据源配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.auth.type', '取值范围:SIMPLE,USERNAME,KERBEROS', 'jdbc认证方式', 'USERNAME', 'OFT', '[\"SIMPLE\",\"USERNAME\",\"KERBEROS\"]', '0', '0', '1', '用户配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.username', 'username', '数据库连接用户名', '', 'None', '', '0', '0', '1', '用户配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.password', 'password', '数据库连接密码', '', 'None', '', '0', '0', '1', '用户配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.principal', '例如:hadoop/host@KDC.COM', '用户principal', '', 'None', '', '0', '0', '1', '用户配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.keytab.location', '例如:/data/keytab/hadoop.keytab', '用户keytab文件路径', '', 'None', '', '0', '0', '1', '用户配置', 'jdbc');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.jdbc.proxy.user.property', '例如:hive.server2.proxy.user', '用户代理配置', '', 'None', '', '0', '0', '1', '用户配置', 'jdbc');
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.engineconn.java.driver.cores', '取值范围:1-8,单位:个', 'jdbc引擎初始化核心个数', '1', 'NumInterval', '[1,8]', '0', '0', '1', 'jdbc引擎设置', 'jdbc');
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.engineconn.java.driver.memory', '取值范围:1-8,单位:G', 'jdbc引擎初始化内存大小', '1g', 'Regex', '^([1-8])(G|g)$', '0', '0', '1', 'jdbc引擎设置', 'jdbc');
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@JDBC_ALL, 'OPTIONAL', 2, now(), now());
insert into `linkis_ps_configuration_key_engine_relation` (`config_key_id`, `engine_type_label_id`)
(select config.id as `config_key_id`, label.id AS `engine_type_label_id` FROM linkis_ps_configuration_config_key config INNER JOIN linkis_cg_manager_label label ON config.engine_conn_type = 'jdbc' and label_value = @JDBC_ALL);
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@JDBC_IDE, 'OPTIONAL', 2, now(), now());
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@JDBC_NODE, 'OPTIONAL', 2, now(), now());
select @label_id := id from linkis_cg_manager_label where `label_value` = @JDBC_IDE;
insert into linkis_ps_configuration_category (`label_id`, `level`) VALUES (@label_id, 2);
select @label_id := id from linkis_cg_manager_label where `label_value` = @JDBC_NODE;
insert into linkis_ps_configuration_category (`label_id`, `level`) VALUES (@label_id, 2);
-- jdbc default configuration
insert into `linkis_ps_configuration_config_value` (`config_key_id`, `config_value`, `config_label_id`)
(select `relation`.`config_key_id` AS `config_key_id`, '' AS `config_value`, `relation`.`engine_type_label_id` AS `config_label_id` FROM linkis_ps_configuration_key_engine_relation relation INNER JOIN linkis_cg_manager_label label ON relation.engine_type_label_id = label.id AND label.label_value = @JDBC_ALL);
如果想重置引擎的数据库配置数据,参考文件如下,请按需进行修改使用:
-- 清除jdbc引擎的初始化数据
SET @JDBC_LABEL="jdbc-4";
SET @JDBC_ALL=CONCAT('*-*,',@JDBC_LABEL);
SET @JDBC_IDE=CONCAT('*-IDE,',@JDBC_LABEL);
SET @JDBC_NODE=CONCAT('*-nodeexecution,',@JDBC_LABEL);
delete from `linkis_ps_configuration_config_value` where `config_label_id` in
(select `relation`.`engine_type_label_id` AS `config_label_id` FROM `linkis_ps_configuration_key_engine_relation` relation INNER JOIN `linkis_cg_manager_label` label ON relation.engine_type_label_id = label.id AND label.label_value = @JDBC_ALL);
delete from `linkis_ps_configuration_key_engine_relation`
where `engine_type_label_id` in
(select label.id FROM `linkis_ps_configuration_config_key` config
INNER JOIN `linkis_cg_manager_label` label
ON config.engine_conn_type = 'jdbc' and label_value = @JDBC_ALL);
delete from `linkis_ps_configuration_category`
where `label_id` in (select id from `linkis_cg_manager_label` where `label_value` in(@JDBC_IDE, @JDBC_NODE));
delete from `linkis_ps_configuration_config_key` where `engine_conn_type` = 'jdbc';
delete from `linkis_cg_manager_label` where `label_value` in (@JDBC_ALL, @JDBC_IDE, @JDBC_NODE);
最终的效果:
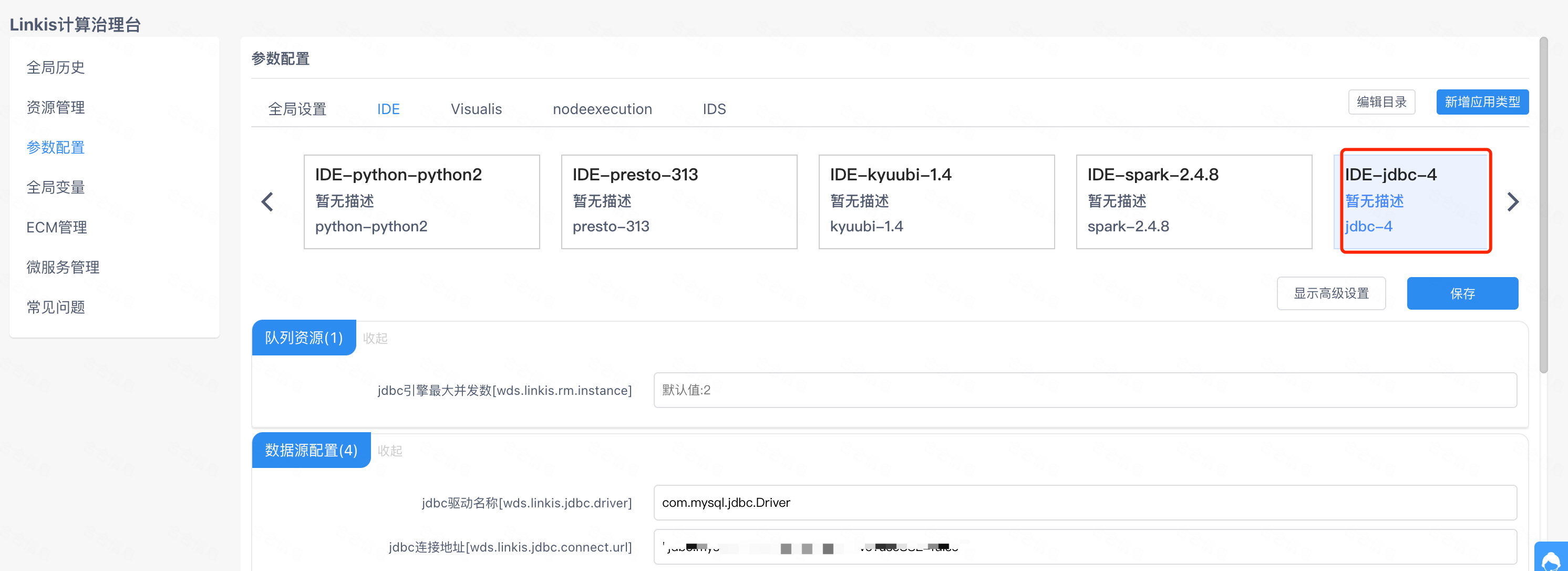
这样配置完之后,linkis-cli以及Scripts提交引擎脚本时,才能正确匹配到引擎的标签信息和数据源的连接信息,然后才能拉起你新加的引擎。
2.9 DSS Scripts中新增JDBC脚本类型以及图标等信息
如果你使用到了DSS的Scripts功能,还需要对dss项目中web的前端文件进行一些小小的改动,改动的目的是为了在Scripts中支持新建、打开、执行JDBC引擎脚本类型,以及实现引擎对应的图标、字体等。
2.9.1 scriptis.js
web/src/common/config/scriptis.js
{
rule: /\.jdbc$/i,
lang: 'hql',
executable: true,
application: 'jdbc',
runType: 'jdbc',
ext: '.jdbc',
scriptType: 'jdbc',
abbr: 'jdbc',
logo: 'fi-jdbc',
color: '#444444',
isCanBeNew: true,
label: 'JDBC',
isCanBeOpen: true
},
2.9.2 脚本复制支持
web/src/apps/scriptis/module/workSidebar/workSidebar.vue
copyName() {
let typeArr = ['......', 'jdbc']
}
2.9.3 logo与字体配色
web/src/apps/scriptis/module/workbench/title.vue
data() {
return {
isHover: false,
iconColor: {
'fi-jdbc': '#444444',
},
};
},
web/src/apps/scriptis/module/workbench/modal.js
let logoList = [
{ rule: /\.jdbc$/i, logo: 'fi-jdbc' },
];
web/src/components/tree/support.js
export const supportTypes = [
// 这里大概没用到
{ rule: /\.jdbc$/i, logo: 'fi-jdbc' },
]
引擎图标展示
web/src/dss/module/resourceSimple/engine.vue
methods: {
calssifyName(params) {
switch (params) {
case 'jdbc':
return 'JDBC';
......
}
}
// 图标过滤
supportIcon(item) {
const supportTypes = [
......
{ rule: 'jdbc', logo: 'fi-jdbc' },
];
}
}
web/src/dss/assets/projectIconFont/iconfont.css
.fi-jdbc:before {
content: "\e75e";
}
此处控制的应该是:
![]()
找一个引擎图标的svg文件
web/src/components/svgIcon/svg/fi-jdbc.svg
如果新引擎后续需要贡献社区,那么新引擎对应的svg图标、字体等需要确认其所属的开源协议,或获取其版权许可。
2.10 DSS的工作流适配
最终达成的效果:
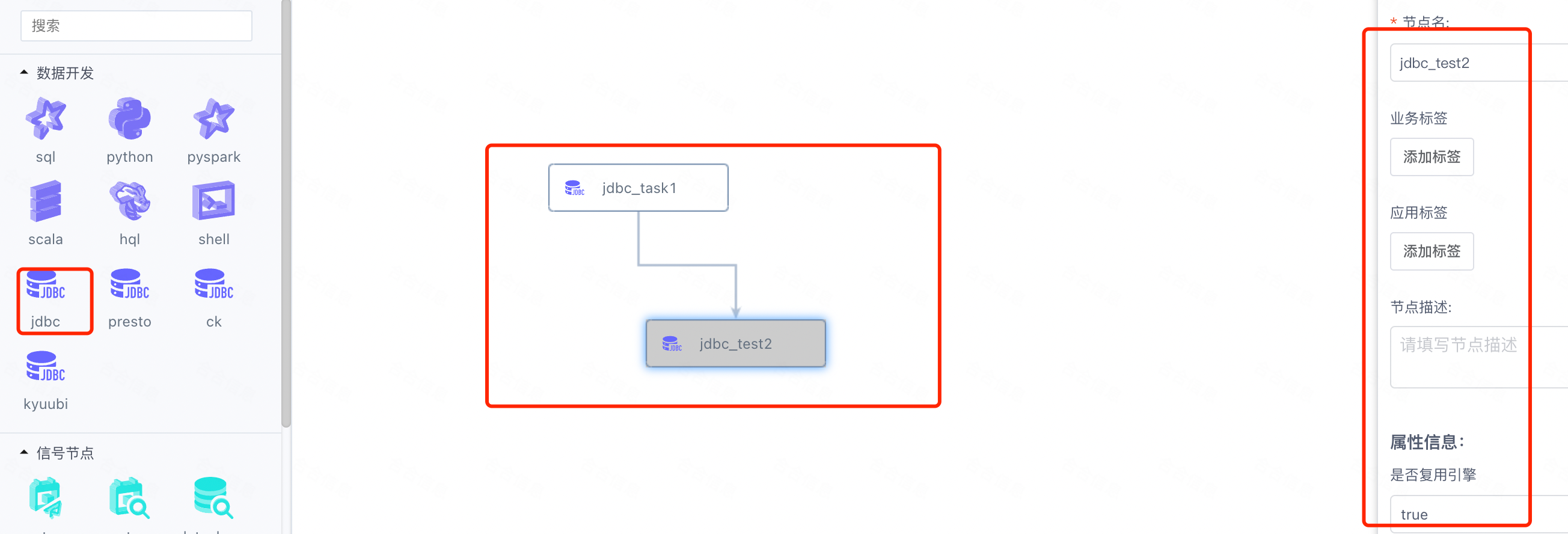
在dss_workflow_node表中保存新加JDBC引擎的定义数据,参考SQL:
# 引擎任务节点基本信息定义
insert into `dss_workflow_node` (`id`, `name`, `appconn_name`, `node_type`, `jump_url`, `support_jump`, `submit_to_scheduler`, `enable_copy`, `should_creation_before_node`, `icon`) values('18','jdbc','-1','linkis.jdbc.jdbc',NULL,'1','1','1','0','svg文件');
# svg文件对应新引擎任务节点图标
# 引擎任务节点分类划分
insert into `dss_workflow_node_to_group`(`node_id`,`group_id`) values (18, 2);
# 引擎任务节点的基本信息(参数属性)绑定
INSERT INTO `dss_workflow_node_to_ui`(`workflow_node_id`,`ui_id`) VALUES (18,45);
# 在dss_workflow_node_ui表中定义了引擎任务节点相关的基本信息,然后以表单的形式在上图右侧中展示,你可以为新引擎扩充其他基础信息,然后自动被右侧表单渲染。
web/src/apps/workflows/service/nodeType.js
import jdbc from '../module/process/images/newIcon/jdbc.svg';
const NODETYPE = {
......
JDBC: 'linkis.jdbc.jdbc',
}
const ext = {
......
[NODETYPE.JDBC]: 'jdbc',
}
const NODEICON = {
[NODETYPE.JDBC]: {
icon: jdbc,
class: {'jdbc': true}
},
}
在web/src/apps/workflows/module/process/images/newIcon/目录下增加新引擎的图标
web/src/apps/workflows/module/process/images/newIcon/jdbc
同样贡献社区时,请考虑svg文件的lincese或版权。
3. 本章小结
上述内容记录了新引擎的实现流程,以及额外需要做的一些引擎配置。目前,一个新引擎的扩展流程还是比较繁琐的,希望能在后续版本中,优化新引擎的扩展、以及安装等过程。