JDBC 引擎
本文主要介绍在Linkis1.X中,JDBC引擎的配置、部署和使用。
1. 环境准备
如果您希望在您的服务器上使用JDBC引擎,您需要准备JDBC连接信息,如MySQL数据库的连接地址、用户名和密码等
2. 部署和配置
2.1 版本的选择和编译
注意: 编译jdbc引擎之前需要进行linkis项目全量编译
发布的安装部署包中默认不包含此引擎插件,
你可以按此指引部署安装 https://linkis.apache.org/zh-CN/blog/2022/04/15/how-to-download-engineconn-plugin
,或者按以下流程,手动编译部署
单独编译jdbc引擎
${linkis_code_dir}/linkis-engineconn-plugins/jdbc/
mvn clean install
2.2 物料的部署和加载
将 2.1 步编译出来的引擎包,位于
${linkis_code_dir}/linkis-engineconn-plugins/jdbc/target/out/jdbc
上传到服务器的引擎目录下
${LINKIS_HOME}/lib/linkis-engineconn-plugins
并重启linkis-cg-linkismanager(或则通过引擎接口进行刷新)
cd ${LINKIS_HOME}/sbin
sh linkis-daemon.sh restart linkis-cg-linkismanager
2.3 引擎的标签
Linkis1.X是通过标签来进行的,所以需要在我们数据库中插入数据,插入的方式如下文所示。
3.JDBC引擎的使用
准备操作
您需要配置JDBC的连接信息,包括连接地址信息和用户名以及密码。
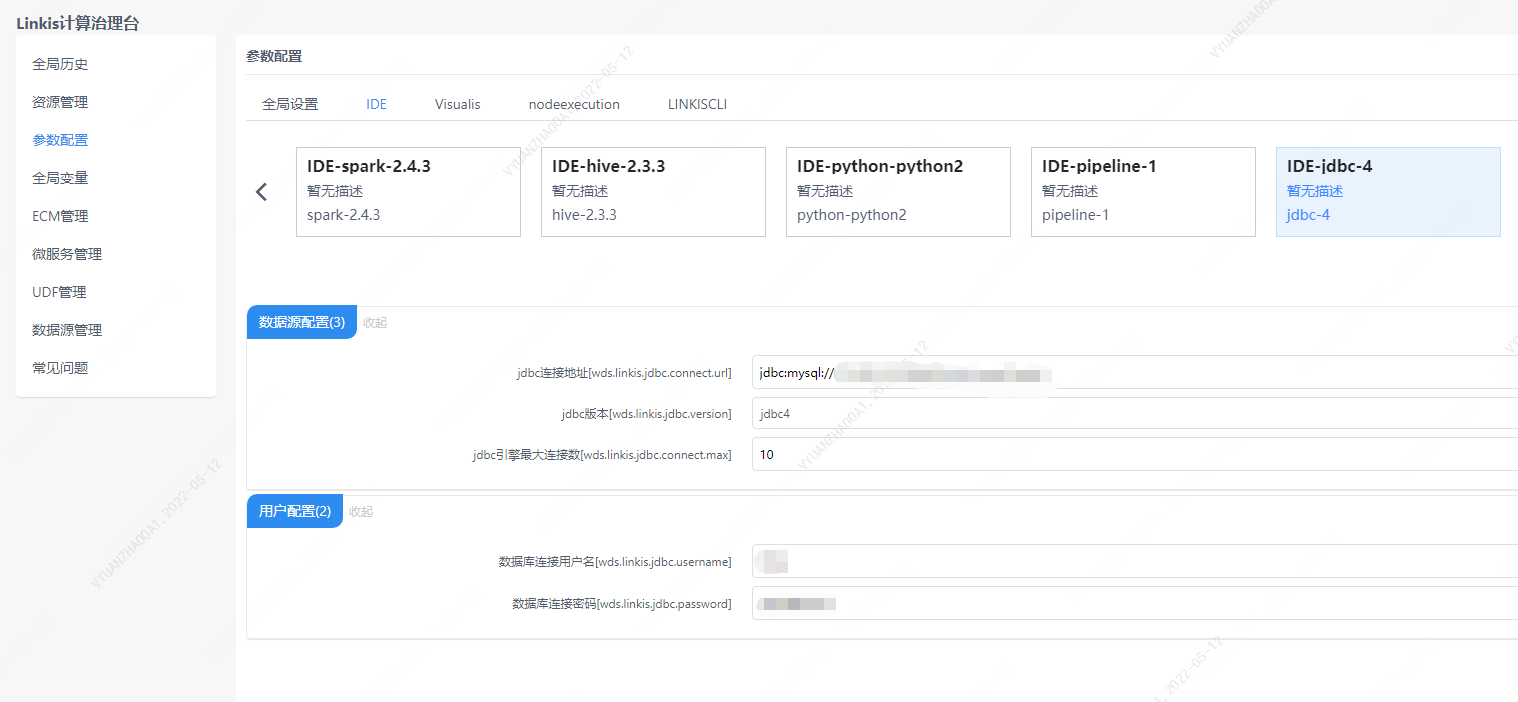
图3-1 JDBC配置信息
您也可以再提交任务接口中的params.configuration.runtime进行修改即可
wds.linkis.jdbc.connect.url
wds.linkis.jdbc.driver
wds.linkis.jdbc.username
wds.linkis.jdbc.password
您也可以在提交任务接口,通过参数进行配置
http 请求参数示例
{
"executionContent": {"code": "show databases;", "runType": "jdbc"},
"params": {
"variable": {},
"configuration": {
"runtime": {
"wds.linkis.jdbc.connect.url":"jdbc:mysql://127.0.0.1:3306/test",
"wds.linkis.jdbc.driver":"com.mysql.jdbc.Driver",
"wds.linkis.jdbc.username":"test",
"wds.linkis.jdbc.password":"test23"
}
}
},
"source": {"scriptPath": "file:///mnt/bdp/hadoop/1.sql"},
"labels": {
"engineType": "jdbc-4",
"userCreator": "hadoop-IDE"
}
}
3.1 通过Linkis SDK进行使用
Linkis提供了Java和Scala 的SDK向Linkis服务端提交任务. 具体可以参考 JAVA SDK Manual. 对于JDBC任务您只需要修改Demo中的EngineConnType和CodeType参数即可:
Map<String, Object> labels = new HashMap<String, Object>();
labels.put(LabelKeyConstant.ENGINE_TYPE_KEY, "jdbc-4"); // required engineType Label
labels.put(LabelKeyConstant.USER_CREATOR_TYPE_KEY, "hadoop-IDE");// required execute user and creator
labels.put(LabelKeyConstant.CODE_TYPE_KEY, "jdbc"); // required codeType
3.2 通过Linkis-cli进行任务提交
Linkis 1.0后提供了cli的方式提交任务,我们只需要指定对应的EngineConn和CodeType标签类型即可,JDBC的使用如下:
sh ./bin/linkis-cli -engineType jdbc-4 -codeType jdbc -code "show tables" -submitUser hadoop -proxyUser hadoop
具体使用可以参考: Linkis CLI Manual.
3.3 Scriptis的使用方式
Scriptis的使用方式是最简单的,您可以直接进入Scriptis,右键目录然后新建JDBC脚本并编写JDBC代码并点击执行。
JDBC的执行原理是通过加载JDBC的Driver然后提交sql到SQL的server去执行并获取到结果集并返回。

图3-2 JDBC的执行效果截图
3.4 多数据源支持
从Linkis 1.2.0开始,提供了JDBC引擎多数据源的支持,我们首先可以在控制台管理不同的数据源。地址:登陆管理台-->数据源管理-->新增数据源

图3-3 数据源管理
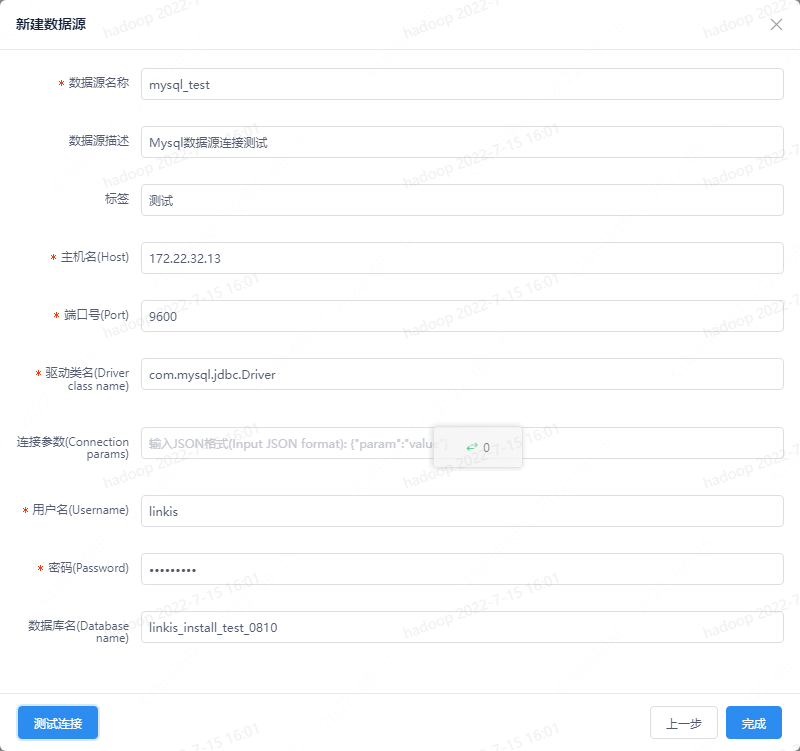
图3-4 数据源连接测试
数据源添加完成之后,就可以使用JDBC引擎的多数据源切换功能,有两种方式: 1、 通过接口参数指定数据源名称参数 参数示例:
{
"executionContent": {
"code": "show databases",
"runType": "jdbc"
},
"params": {
"variable": {},
"configuration": {
"startup": {},
"runtime": {
"wds.linkis.engine.runtime.datasource": "test_mysql"
}
}
},
"source": {
"scriptPath": ""
},
"labels": {
"engineType": "jdbc-4",
"userCreator": "hadoop-IDE"
}
}
参数:wds.linkis.engine.runtime.datasource为固定名称的配置,不要随意修改名称定义
2、通过DSS的Scripts代码提交入口下拉筛选需要提交的数据源,如下图:
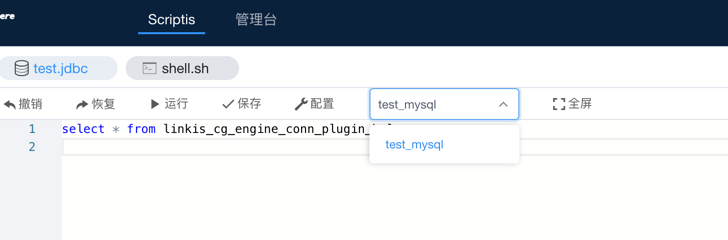 当前dss-1.1.0还暂不支持下拉选择数据源名称,PR在开发中,可以等后续发版或关注相关PR:
(https://github.com/WeBankFinTech/DataSphereStudio/issues/940)
当前dss-1.1.0还暂不支持下拉选择数据源名称,PR在开发中,可以等后续发版或关注相关PR:
(https://github.com/WeBankFinTech/DataSphereStudio/issues/940)
多数据源的功能说明:
1)在之前的版本中,JDBC引擎对数据源的支持不够完善,尤其是搭配Scripts使用的时候,jdbc脚本类型只能绑定控制台的一套JDBC引擎参数, 当我们有多数据源的切换需求时,只能修改jdbc引擎的连接参数,比较麻烦。
2)配合数据源管理,我们引入JDBC引擎的多数据源切换功能,可以实现只设置数据源名称,就可把作业提交到不同的JDBC服务之上,普通用户不需要 维护数据源的连接信息,避免了配置繁琐,也满足了数据源连接密码等配置的安全性需要。
3)多数据源管理中设置的数据源,只有发布之后,并且没有过期的数据源才能被JDBC引擎加载到,否则会反馈给用户不同类型的异常提示。
4)jdbc引擎参数的加载优先级为:任务提交传参 > 选择数据源的参数 > 控制台JDBC引擎的参数
4.JDBC引擎的用户设置
JDBC的用户设置是主要是的JDBC的连接信息,但是建议用户将此密码等信息进行加密管理。