快速部署
1. 注意事项
因为mysql-connector-java驱动是GPL2.0协议,不满足Apache开源协议关于license的政策,因此从1.0.3版本开始,提供的Apache版本官方部署包,默认是没有mysql-connector-java-x.x.x.jar的依赖包,安装部署时需要添加依赖到对应的lib包中。
安装过程中遇到的问题,可以参考排障指引 https://linkis.apache.org/zh-CN/blog/2022/02/21/linkis-deploy
如果您是首次接触并使用Linkis,您可以忽略该章节;如果您已经是 Linkis 的使用用户,安装或升级前建议先阅读:Linkis1.0 与 Linkis0.X 的区别简述。
请注意:除了 Linkis1.0 安装包默认已经包含的:Python/Shell/Hive/Spark四个EngineConnPlugin以外,如果大家有需要,可以手动安装如 JDBC 引擎等类型的其他引擎,具体请参考 EngineConnPlugin引擎插件安装文档。
Linkis1.0.3 默认已适配的引擎列表如下:
| 引擎类型 | 适配情况 | 官方安装包是否包含 |
|---|---|---|
| Python | 1.0已适配 | 包含 |
| JDBC | 1.0已适配 | 不包含 |
| Flink | 1.0已适配 | 不包含 |
| Shell | 1.0已适配 | 包含 |
| Hive | 1.0已适配 | 包含 |
| Spark | 1.0已适配 | 包含 |
| Pipeline | 1.0已适配 | 不包含 |
| Presto | 1.0未适配 | 不包含 |
| ElasticSearch | 1.0未适配 | 不包含 |
| Impala | 1.0未适配 | 不包含 |
| MLSQL | 1.0未适配 | 不包含 |
| TiSpark | 1.0未适配 | 不包含 |
2. 确定您的安装环境
这里给出每个引擎的依赖信息列表:
| 引擎类型 | 依赖环境 | 特殊说明 |
|---|---|---|
| Python | Python环境 | 日志和结果集如果配置hdfs://则依赖HDFS环境 |
| JDBC | 可以无依赖 | 日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
| Shell | 可以无依赖 | 日志和结果集路径如果配置hdfs://则依赖HDFS环境 |
| Hive | 依赖Hadoop和Hive环境 | |
| Spark | 依赖Hadoop/Hive/Spark |
要求:安装Linkis需要至少3G内存。
默认每个微服务JVM堆内存为512M,可以通过修改SERVER_HEAP_SIZE来统一调整每个微服务的堆内存,如果您的服务器资源较少,我们建议修改该参数为128M。如下:
vim ${LINKIS_HOME}/deploy-config/linkis-env.sh
# java application default jvm memory.
export SERVER_HEAP_SIZE="128M"
3. Linkis环境准备
3.1 基础软件安装
下面的软件必装:
3.2 创建用户
例如: 部署用户是hadoop账号
- 在部署机器上创建部署用户,用于安装
sudo useradd hadoop
- 因为Linkis的服务是以 sudo -u ${linux-user} 方式来切换引擎,从而执行作业,所以部署用户需要有 sudo 权限,而且是免密的。
vi /etc/sudoers
hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL
在每台安装节点设置如下的全局环境变量,以便Linkis能正常使用Hadoop、Hive和Spark。
修改安装用户的.bash_rc,命令如下:
vim /home/hadoop/.bash_rc ##以部署用户Hadoop为例
下方为环境变量示例:
#JDK
export JAVA_HOME=/nemo/jdk1.8.0_141
##如果不使用Hive、Spark等引擎且不依赖Hadoop,则不需要修改以下环境变量
#HADOOP
export HADOOP_HOME=/appcom/Install/hadoop
export HADOOP_CONF_DIR=/appcom/config/hadoop-config
#Hive
export HIVE_HOME=/appcom/Install/hive
export HIVE_CONF_DIR=/appcom/config/hive-config
#Spark
export SPARK_HOME=/appcom/Install/spark
export SPARK_CONF_DIR=/appcom/config/spark-config/
export PYSPARK_ALLOW_INSECURE_GATEWAY=1 # Pyspark必须加的参数
- 如果您的Pyspark和Python想拥有画图功能,则还需在所有安装节点,安装画图模块。命令如下:
python -m pip install matplotlib
3.3 安装包准备
从Linkis已发布的release中(点击这里进入下载页面),下载最新的安装包。
先解压安装包到安装目录,并对解压后的文件进行配置修改。
#version >=1.0.3
tar -xvf apache-linkis-x.x.x-incubating-bin.tar.gz
3.4 依赖HDFS/Hive/Spark的基础配置修改
vi deploy-config/linkis-env.sh
SSH_PORT=22 #指定SSH端口,如果单机版本安装可以不配置
deployUser=hadoop #指定部署用户
WORKSPACE_USER_ROOT_PATH=file:///tmp/hadoop # 指定用户根目录,一般用于存储用户的脚本文件和日志文件等,是用户的工作空间。
RESULT_SET_ROOT_PATH=hdfs:///tmp/linkis # 结果集文件路径,用于存储Job的结果集文件
ENGINECONN_ROOT_PATH=/appcom/tmp #存放ECP的安装路径,需要部署用户有写权限的本地目录
ENTRANCE_CONFIG_LOG_PATH=hdfs:///tmp/linkis/ #ENTRANCE的日志路径
#因为1.0支持多Yarn集群,使用到Yarn队列资源的一定需要配置YARN_RESTFUL_URL
YARN_RESTFUL_URL=http://127.0.0.1:8088 #Yarn的ResourceManager的地址
# 如果您想配合Scriptis一起使用,CDH版的Hive,还需要配置如下参数(社区版Hive可忽略该配置)
HIVE_META_URL=jdbc://... # HiveMeta元数据库的URL
HIVE_META_USER= # HiveMeta元数据库的用户
HIVE_META_PASSWORD= # HiveMeta元数据库的密码
# 配置hadoop/hive/spark的配置目录
HADOOP_CONF_DIR=/appcom/config/hadoop-config #hadoop的conf目录
HIVE_CONF_DIR=/appcom/config/hive-config #hive的conf目录
SPARK_CONF_DIR=/appcom/config/spark-config #spark的conf目录
## LDAP配置,默认Linkis只支持部署用户登录,如果需要支持多用户登录可以使用LDAP,需要配置以下参数:
#LDAP_URL=ldap://localhost:1389/
#LDAP_BASEDN=
##如果spark不是2.4.3的版本需要修改参数:
#SPARK_VERSION=3.1.1
##如果hive不是1.2.1的版本需要修改参数:
#HIVE_VERSION=2.3.3
3.5 修改数据库配置
vi deploy-config/db.sh
# 设置数据库的连接信息
# 包括IP地址、数据库名称、用户名、端口
# 主要用于存储用户的自定义变量、配置参数、UDF和小函数,以及提供JobHistory的底层存储
MYSQL_HOST=
MYSQL_PORT=
MYSQL_DB=
MYSQL_USER=
MYSQL_PASSWORD=
4. 安装和启动
4.1 执行安装脚本:
sh bin/install.sh
linkis默认是使用静态用户和密码,静态用户即部署用户,静态密码会在执行部署是随机生成一个密码串,存储于{installPath}/conf/linkis-mg-gateway.properties(>=1.0.3版本)
4.2 安装步骤
- install.sh脚本会询问您是否需要初始化数据库并导入元数据。
因为担心用户重复执行install.sh脚本,把数据库中的用户数据清空,所以在install.sh执行时,会询问用户是否需要初始化数据库并导入元数据。
第一次安装必须选是。
请注意:如果您是升级已有环境的 Linkis0.X 到 Linkis1.0,请不要直接选是,请先参考 Linkis1.0升级指南。
请注意:如果您是升级已有环境的 Linkis0.X 到 Linkis1.0,请不要直接选是,请先参考 Linkis1.0升级指南。
请注意:如果您是升级已有环境的 Linkis0.X 到 Linkis1.0,请不要直接选是,请先参考 Linkis1.0升级指南。
4.3 是否安装成功:
通过查看控制台打印的日志信息查看是否安装成功。
如果有错误信息,可以查看具体报错原因。
您也可以通过查看我们的常见问题,获取问题的解答。
4.4 添加mysql驱动包
因为mysql-connector-java驱动是GPL2.0协议,不满足Apache开源协议关于license的政策,因此从1.0.3版本开始,提供的Apache版本官方部署包,默认是没有mysql-connector-java-x.x.x.jar的依赖包,安装部署时需要自行添加依赖到对应的lib包中
下载mysql驱动 以5.1.49版本为例:下载链接 https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar
拷贝mysql 驱动包至lib包下
cp mysql-connector-java-5.1.49.jar ${LINKIS_HOME}/lib/linkis-spring-cloud-services/linkis-mg-gateway/
cp mysql-connector-java-5.1.49.jar ${LINKIS_HOME}/lib/linkis-commons/public-module/
4.5 快速启动Linkis
(1)、启动服务:
在安装目录执行以下命令,启动所有服务:
sh sbin/linkis-start-all.sh
(2)、查看是否启动成功
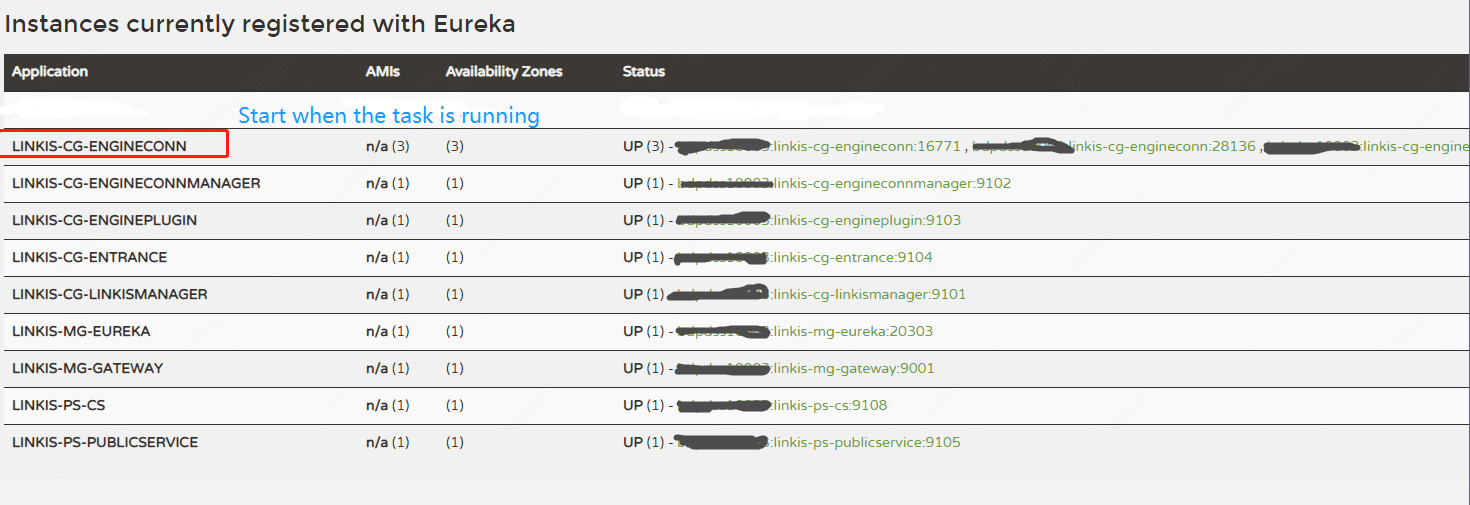
可以在Eureka界面查看服务启动成功情况,查看方法:
使用http://${EUREKA_INSTALL_IP}:${EUREKA_PORT}, 在浏览器中打开,查看服务是否注册成功。
如果您没有在config.sh指定EUREKA_INSTALL_IP和EUREKA_INSTALL_IP,则HTTP地址为:http://127.0.0.1:20303
如下图,如您的Eureka主页出现以下微服务,则表示服务都启动成功,可以正常对外提供服务了:
默认会启动8个Linkis微服务,其中图下linkis-cg-engineconn服务为运行任务才会启动
(3)、查看服务是否正常
- 服务启动成功后您可以通过,安装前端管理台,来检验服务的正常性,点击跳转管理台安装文档
- 您也可以通过Linkis用户手册来测试Linis是否能正常运行任务,点击跳转用户手册