EngineConn 新增流程
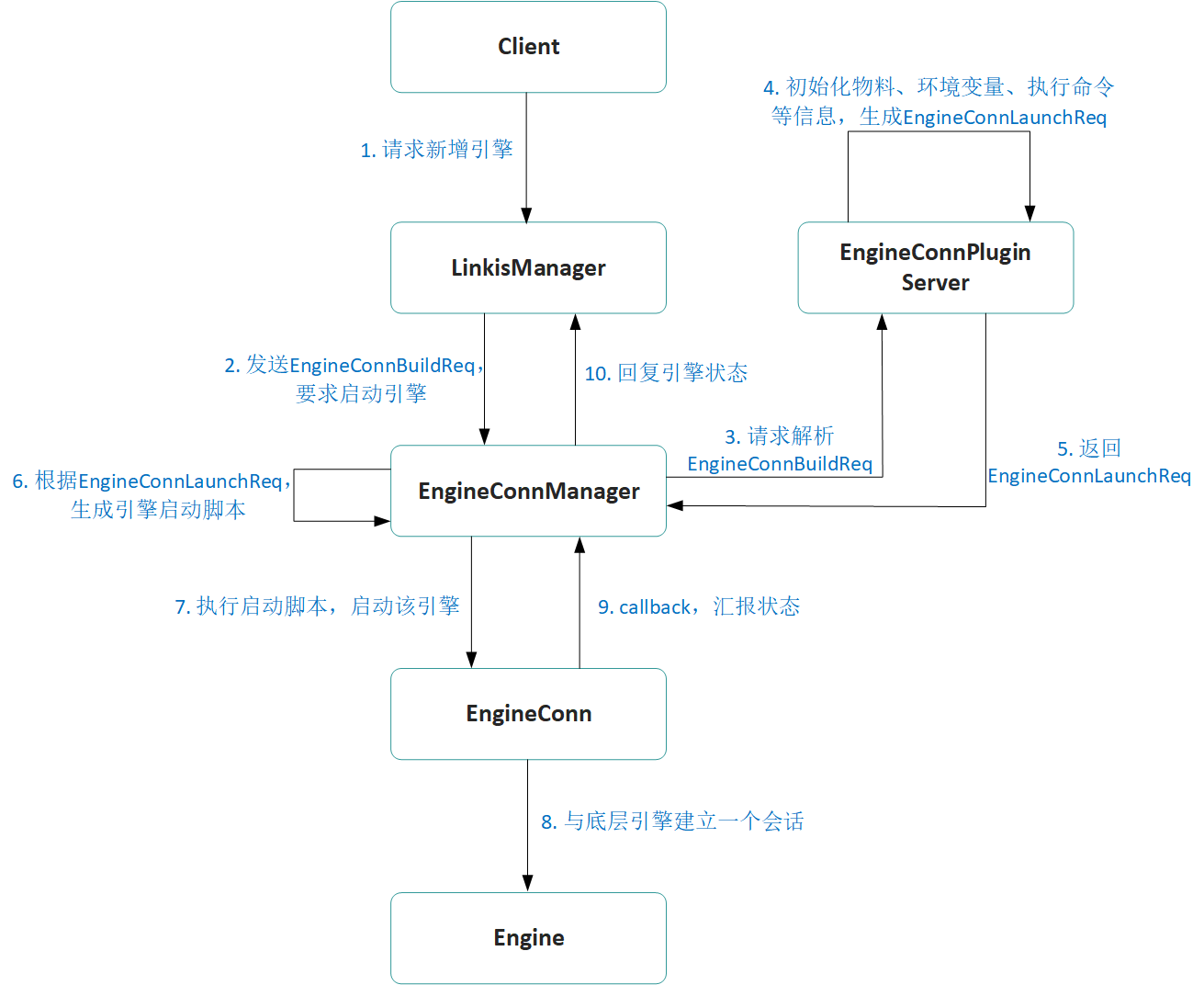
EngineConn的新增,是Linkis计算治理的计算任务准备阶段的核心流程之一。它主要包括了Client端(Entrance或用户客户端)向LinkisManager发起一个新增EngineConn的请求,LinkisManager为用户按需、按标签规则,向EngineConnManager发起一个启动EngineConn的请求,并等待EngineConn启动完成后,将可用的EngineConn返回给Client的整个流程。
如下图所示,接下来我们来详细说明一下整个流程:
1. LinkisManager接收客户端请求
名词解释:
LinkisManager:是Linkis计算治理能力的管理中枢,主要的职责为:
基于多级组合标签,为用户提供经过复杂路由、资源管控和负载均衡后的可用EngineConn;
提供EC和ECM的全生命周期管理能力;
为用户提供基于多级组合标签的多Yarn集群资源管理功能。主要分为 AppManager(应用管理器)、ResourceManager(资源管理器)、LabelManager(标签管理器)三大模块,能够支持多活部署,具备高可用、易扩展的特性。
AM模块接收到Client的新增EngineConn请求后,首先会对请求做参数校验,判断请求参数的合法性;其次是通过复杂规则选中一台最合适的EngineConnManager(ECM),以用于后面的EngineConn启动;接下来会向RM申请启动该EngineConn需要的资源;最后是向ECM请求创建EngineConn。
下面将对四个步骤进行详细说明。
1.1 请求参数校验
AM模块在接受到引擎创建请求后首先会做参数判断,首先会做请求用户和创建用户的权限判断,接着会对请求带上的Label进行检查。因为在AM后续的创建流程当中,Label会用来查找ECM和进行资源信息记录等,所以需要保证拥有必须的Label,现阶段一定需要带上的Label有UserCreatorLabel(例:hadoop-IDE)和EngineTypeLabel(例:spark-2.4.3)。
1.2 EngineConnManager(ECM)选择
ECM选择主要是完成通过客户端传递过来的Label去选择一个合适的ECM服务去启动EngineConn。这一步中首先会通过LabelManager去通过客户端传递过来的Label去注册的ECM中进行查找,通过按照标签匹配度进行顺序返回。在获取到注册的ECM列表后,会对这些ECM进行规则选择,现阶段已经实现有可用性检查、资源剩余、机器负载等规则。通过规则选择后,会将标签最匹配、资源最空闲、负载低的ECM进行返回。
1.3 EngineConn资源申请
在获取到分配的ECM后,AM接着会通过调用EngineConnPluginServer服务请求本次客户端的引擎创建请求会使用多少的资源,这里会通过封装资源请求,主要包含Label、Client传递过来的EngineConn的启动参数、以及从Configuration模块获取到用户配置参数,通过RPC调用ECP服务去获取本次的资源信息。
EngineConnPluginServer服务在接收到资源请求后,会先通过传递过来的标签找到对应的引擎标签,通过引擎标签选择对应引擎的EngineConnPlugin。然后通过EngineConnPlugin的资源生成器,对客户端传入的引擎启动参数进行计算,算出本次申请新EngineConn所需的资源,然后返回给LinkisManager。
名词解释:
EgineConnPlugin:是Linkis对接一个新的计算存储引擎必须要实现的接口,该接口主要包含了这种EngineConn在启动过程中必须提供的几个接口能力,包括EngineConn资源生成器、EngineConn启动命令生成器、EngineConn引擎连接器。具体的实现可以参考Spark引擎的实现类:SparkEngineConnPlugin。
EngineConnPluginServer:是加载了所有的EngineConnPlugin,对外提供EngineConn的所需资源生成能力和EngineConn的启动命令生成能力的微服务。
EngineConnPlugin资源生成器(EngineConnResourceFactory):通过传入的参数,计算出本次EngineConn启动时需要的总资源。
EngineConn启动命令生成器(EngineConnLaunchBuilder):通过传入的参数,生成该EngineConn的启动命令,以提供给ECM去启动引擎。
- AM在获取到引擎资源后,会接着调用RM服务去申请资源,RM服务会通过传入的Label、ECM、本次申请的资源,去进行资源判断。首先会判断客户端对应Label的资源是否足够,然后再会判断ECM服务的资源是否足够,如果资源足够,则本次资源申请通过,并对对应的Label进行资源的加减。
1.4 请求ECM创建引擎
- 在完成引擎的资源申请后,AM会封装引擎启动的请求,通过RPC发送给对应的ECM进行服务启动,并获取到EngineConn的实例对象;
- AM接着会去通过EngineConn的上报信息判断EngineConn是否启动成功变成可用状态,如果是就会将结果进行返回,本次新增引擎的流程也就结束。
2. ECM启动EngineConn
名词解释:
EngineConnManager(ECM):EngineConn的管理器,提供引擎的生命周期管理,同时向RM汇报负载信息和自身的健康状况。
EngineConnBuildRequest:LinkisManager传递给ECM的启动引擎命令,里面封装了该引擎的所有标签信息、所需资源和一些参数配置信息。
EngineConnLaunchRequest:包含了启动一个EngineConn所需的BML物料、环境变量、ECM本地必需环境变量、启动命令等信息,让ECM可以依此构建出一个完整的EngineConn启动脚本。
ECM接收到LinkisManager传递过来的EngineConnBuildRequest命令后,主要分为三步来启动EngineConn:1. 请求EngineConnPluginServer,获取EngineConnPluginServer封装出的EngineConnLaunchRequest;2. 解析EngineConnLaunchRequest,封装成EngineConn启动脚本;3. 执行启动脚本,启动EngineConn。
2.1 EngineConnPluginServer封装EngineConnLaunchRequest
通过EngineConnBuildRequest的标签信息,拿到实际需要启动的EngineConn类型和对应版本,从EngineConnPluginServer的内存中获取到该EngineConn类型的EngineConnPlugin,通过该EngineConnPlugin的EngineConnLaunchBuilder,将EngineConnBuildRequest转换成EngineConnLaunchRequest。
2.2 封装EngineConn启动脚本
ECM获取到EngineConnLaunchRequest之后,将EngineConnLaunchRequest中的BML物料下载到本地,并检查EngineConnLaunchRequest要求的本地必需环境变量是否存在,校验通过后,将EngineConnLaunchRequest封装成一个EngineConn启动脚本
2.3 执行启动脚本
目前ECM只对Unix系统做了Bash命令的支持,即只支持Linux系统执行该启动脚本。
启动前,会通过sudo命令,切换到对应的请求用户去执行该脚本,确保启动用户(即JVM用户)为Client端的请求用户。
执行该启动脚本后,ECM会实时监听脚本的执行状态和执行日志,一旦执行状态返回非0,则立马向LinkisManager汇报EngineConn启动失败,整个流程完成;否则则一直监听启动脚本的日志和状态,直到该脚本执行完成。
3. EngineConn初始化
ECM执行了EngineConn的启动脚本后,EngineConn微服务正式启动。
名词解释:
EngineConn微服务:指包含了一个EngineConn、一个或多个Executor,用于对计算任务提供计算能力的实际微服务。我们说的新增一个EngineConn,其实指的就是新增一个EngineConn微服务。
EngineConn:引擎连接器,是与底层计算存储引擎的实际连接单元,包含了与实际引擎的会话信息。它与Executor的差别,是EngineConn只是起到一个连接、一个客户端的作用,并不真正的去执行计算。如SparkEngineConn,其会话信息为SparkSession。
Executor:执行器,作为真正的计算存储场景执行器,是实际的计算存储逻辑执行单元,对EngineConn各种能力的具体抽象,提供交互式执行、订阅式执行、响应式执行等多种不同的架构能力。
EngineConn微服务的初始化一般分为三个阶段:
初始化具体引擎的EngineConn。先通过Java main方法的命令行参数,封装出一个包含了相关标签信息、启动信息和参数信息的EngineCreationContext,通过EngineCreationContext初始化EngineConn,完成EngineConn与底层Engine的连接建立,如:SparkEngineConn会在该阶段初始化一个SparkSession,用于与一个Spark application建立了连通关系。
初始化Executor。EngineConn初始化之后,接下来会根据实际的使用场景,初始化对应的Executor,为接下来的用户使用,提供服务能力。比如:交互式计算场景的SparkEngineConn,会初始化一系列可以用于提交执行SQL、PySpark、Scala代码能力的Executor,支持Client往该SparkEngineConn提交执行SQL、PySpark、Scala等代码。
定时向LinkisManager汇报心跳,并等待EngineConn结束退出。当EngineConn对应的底层引擎异常、或是超过最大空闲时间、或是Executor执行完成、或是用户手动kill时,该EngineConn自动结束退出。
到了这里,EngineConn的新增流程就基本结束了,最后我们再来总结一下EngineConn的新增流程:
客户端向LinkisManager发起新增EngineConn的请求;
LinkisManager校验参数合法性,先是根据标签选择合适的ECM,再根据用户请求确认本次新增EngineConn所需的资源,向LinkisManager的RM模块申请资源,申请通过后要求ECM按要求启动一个新的EngineConn;
ECM先请求EngineConnPluginServer获取一个包含了启动一个EngineConn所需的BML物料、环境变量、ECM本地必需环境变量、启动命令等信息的EngineConnLaunchRequest,然后封装出EngineConn的启动脚本,最后执行启动脚本,启动该EngineConn;
EngineConn初始化具体引擎的EngineConn,然后根据实际的使用场景,初始化对应的Executor,为接下来的用户使用,提供服务能力。最后定时向LinkisManager汇报心跳,等待正常结束或被用户终止。